I blogged previously on my thoughts about what makes a good lakehouse serving layer - the functionality and features to consider when trying to identify the right serving tool for you.
In this post I want to go a step further and do a direct comparison of some of the more obvious Azure based lakehouse serving tools - Synapse Serverless, Databricks SQL, and Synapse Dedicated. I’ve decided to include Dedicated here, as although it defeats the purpose of the lakehouse paradigm, I’m still often asked whether it’s suitable.
You’ll notice I’ve put 2022 in the title of this blog. This is the type of thing that’ll have a changing landscape as these tools develop further, and new tools emerge, so I wanted to create that distinction now to support future editions of this post.
Functionality Comparison
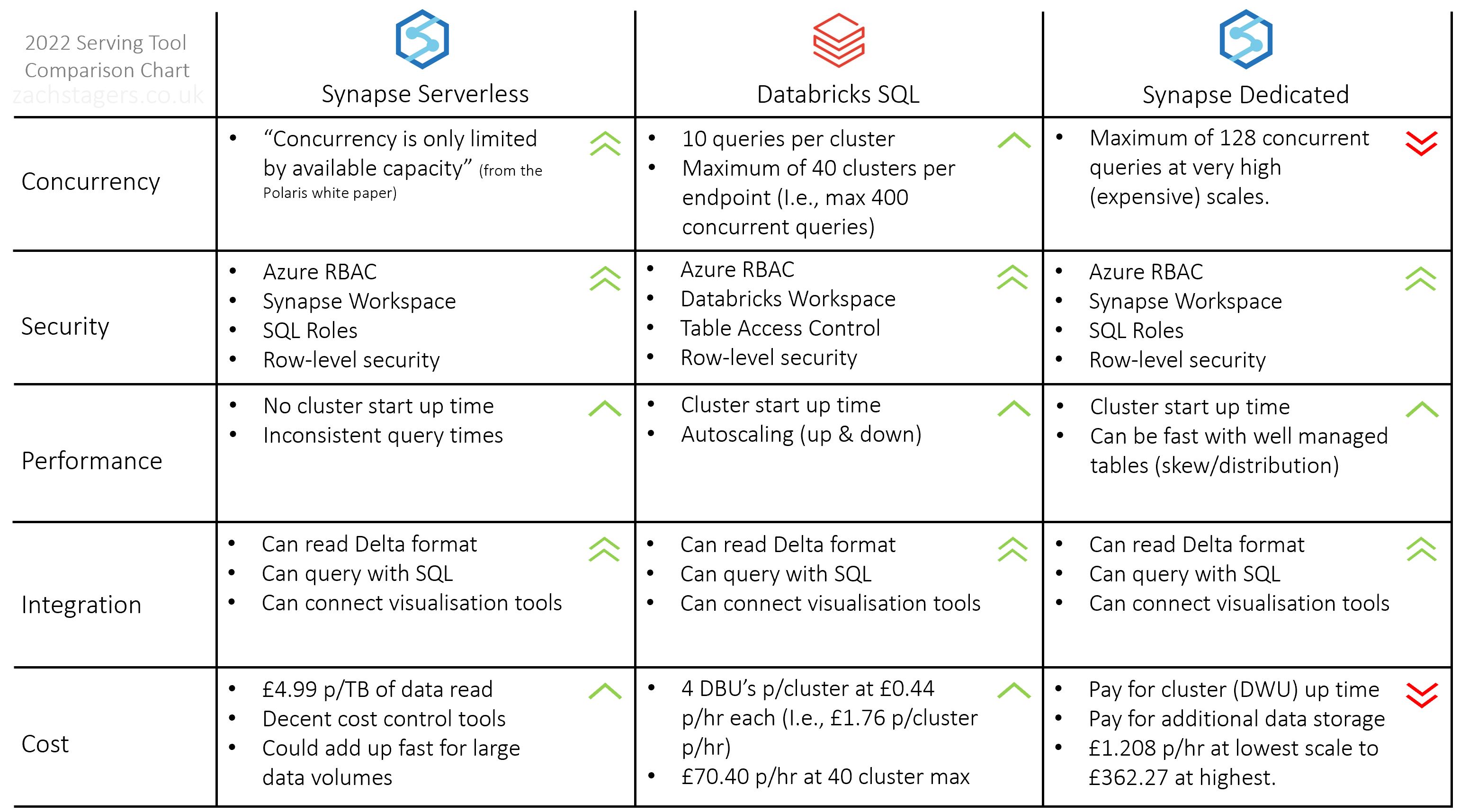
In my previous post, I called out 5 main things to look out for when choosing a tool; Concurrency, Security, Performance, Integration, and Cost. Below I’ve produced a comparison chart across these 5 metrics for the tools in scope for this blog.
For reference, here’s a link to Synapse Serverless' Polaris Engine White Paper.
The comparison chart above condenses a lot of information into a single table, but of course there are other things to consider. Things like the maintenance involved with managing each of those tools, how arduous the set up and configuration is, and their unique abilities (or USP’s).
Setup and Configuration
By setup and configuration, I mean all of the work involved with getting to the point you can actually serve data from the tool - excluding your specific security setup…
Synapse Dedicated
In order to serve out of a dedicated SQL pool, you would first need to ingest the data into that pool. This could potentially include creating credentials, external file formats, external data source, external tables, and using PolyBase, or using the COPY command.
Once the data is into a dedicated pool, it may need merging from staging tables into serving tables using slowly changing techniques (SCD).
That’s quite a lot of configuration, plus you have to pay an additional ~£18 per TB of data stored inside the dedicated pool each month.
Synapse Serverless
Similar to Dedicated, but a little simpler. Here we need to provide a method of reading from the lake which may again include creating credentials, external file formats, and external data sources - plus views over those entities from which to serve, but there’s no PolyBase or COPY or data storage.
I’ve blogged previously about Azure Synapse Serverless Lake Access Patterns, so I won’t go into any more detail on that here.
Databricks SQL
Perhaps the easiest of the lot. Assuming that you’re using Databricks as your processing engine, you probably already have your tables saved within the Hive metastore, which makes them available for querying in Databricks SQL.
If you’re not using Databricks for your processing, then you’d need to mount your lake, create a database, and create your tables specifying the lake location to be read from.
Maintenance
Synapse Dedicated
Managing a Dedicated pool can be quite involved. You need to think about the distribution method used for each table to avoid skew, whether table replication is appropriate, and the more traditional maintenance that comes with indexing.
Synapse Serverless
Aside from ensuring your lake is in order, there really isn’t any maintenance involved with Serverless - that’s the beauty of Polaris. If you’re using the Delta format (you should be) then you’ll want to apply vacuuming and optimising occasionally to keep things tip top.
Databricks SQL
With Databricks SQL you have an endpoint/clusters to monitor and manage, which comes with some overhead. On top of that, you should again ensure your Delta files are in good shape by running a vacuum and optimise every now and then.
Unique Selling Points
Synapse Dedicated
It doesn’t really have any unique serving capabilities when compared to Synapse Serverless and Databricks SQL.
Synapse Serverless
The beauty of Serverless is the Polaris engine. There’s absolutely nothing to manage - no cluster to spin up, or sizing. On the other hand, this means it’s a little black boxy, but there’s plenty of guidance out there about how to optimise serverless queries (hint: use Delta and specify a WITH clause with narrow data types!).
Databricks SQL
Databricks SQL offers the in-built ability to create visualisations, dashboards, and alerts. Meaning, if it caters to all your visualisation needs, and you go all in on Databricks, you may not even need PowerBI licencing! Suddenly the price tag for a Databricks SQL cluster really doesn’t look too bad…
Conclusion
Hopefully this post has helped you decide on how you want to serve your lake. On the surface it may appear that Serverless is the outright winner here, but Databricks SQL is a fantastic option too. If you’re only using Synapse for one of it’s many capabilities (in this case Serverless), the fact you could eliminate it from your architecture all together and therefore not have another resource/workspace to manage is a really big deal.
It feels as though I’ve been pretty harsh on ol' Synapse Dedicated SQL Pools today… but in the age of lakes, it is not king, and I hope to have painted a clear and obvious picture of the reasons why it isn’t suitable for serving a lake-based analytical model.